【Cloudflare 大規模障害から学ぶ】外部のサービスに依存している企業が採るべき「リスク分散」の鉄則

2025年11月18日、世界的に利用者の多い Cloudflare の大規模障害が大きな話題を呼びました。同じタイミングで、ChatGPT や X、Zoom、Microsoft Teams などのサービスにおいてアクセスしづらい状況が相次いだことから、Cloudflare の障害との関連性がニュースサイト等で示唆されました。
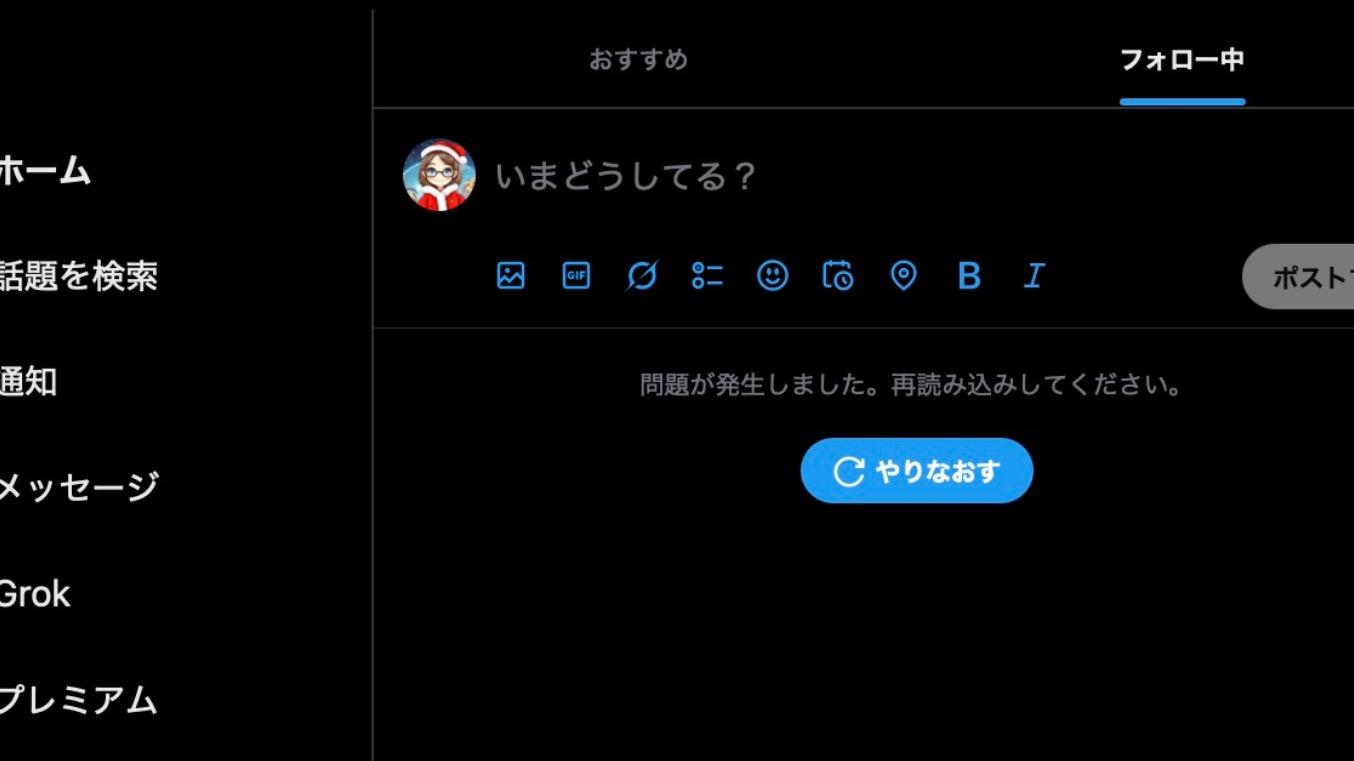
多くの人々が普段当たり前のように使っているサービスでアクセス不調が発生したことは、Cloudflare がさまざまなサービスに活用されているという事実とともに、「私たちの生活や仕事は“外部のサービス”に大きく依存している」という現実を再認識させられる出来事となりました。
本記事では、今回話題となった Cloudflare の障害をきっかけに、Cloudflare がどのような仕組みを担うサービスなのかを改めて整理しつつ、企業が今後認識しておくべきリスクと備えについて考察します。
※本記事はサイバーセキュリティに関する啓発や考察を目的としています。特定の企業・団体を批判する意図は一切ありません。
Cloudflare とは
今回の障害をきっかけに Cloudflare という名前を目にする機会が増えましたが、私たちが普段アクセスしているWebサイトやサービスの多くが、実は Cloudflare によって支えられています。
Webサービスなどをつくる側でなければ意識しづらい領域を担っているため、知る機会がなかった人も多いでしょう。
ここでは、Cloudflare がどのような仕組みでサービスを形成し、その価値を実現しているのかを、以下4つの特徴に分けて整理してみます。
- グローバルCDN(コンテンツ配信ネットワーク)
- アプリケーション層やネットワーク層の防御(DDoS・Bot対策)
- DNS・リバースプロキシ・WAF・エッジコンピューティング
- 世界規模のエッジデータセンター網
グローバルCDN(コンテンツ配信ネットワーク)
世界250カ所以上の拠点に分散したネットワークを利用して、WebサイトやAPIの応答速度を大幅に向上させます。
アプリケーション層やネットワーク層の防御(DDoS・Bot対策)
大規模なDDoS攻撃やBot、レイヤ7(アプリケーション層)の攻撃などからWebサービスを守るため、業界最大規模の防御基盤を運用しています。
DNS・リバースプロキシ・WAF・エッジコンピューティング
Cloudflare は、Webサイトに「アクセスが到達するまでの入口部分」をまとめて担当しています。具体的には、DNSで「どこに接続するか」を素早く案内し、リバースプロキシで悪意あるアクセスを手前で止め、WAFで不審な通信をブロックし、必要であればエッジ側でコードを実行して処理を軽くします。
つまり、ユーザーのアクセスがサービスに届く前に、速度と安全性を高める「玄関口の管理」を一手に引き受ける仕組みです。
世界規模のエッジデータセンター網
Cloudflare は世界中に多数の拠点(データセンター)を持っていて、ユーザーがどこからアクセスしても、できるだけ近い場所で処理できるようになっています。これにより、通信が速くなるだけでなく、どこかの地域で障害が起きても別ルートに切り替えてサービスを継続できます。要するに、「世界中にある中継ポイント」でアクセスを最適化し、速さと安定性を両立しています。
今回の障害で何が起きていたのか?
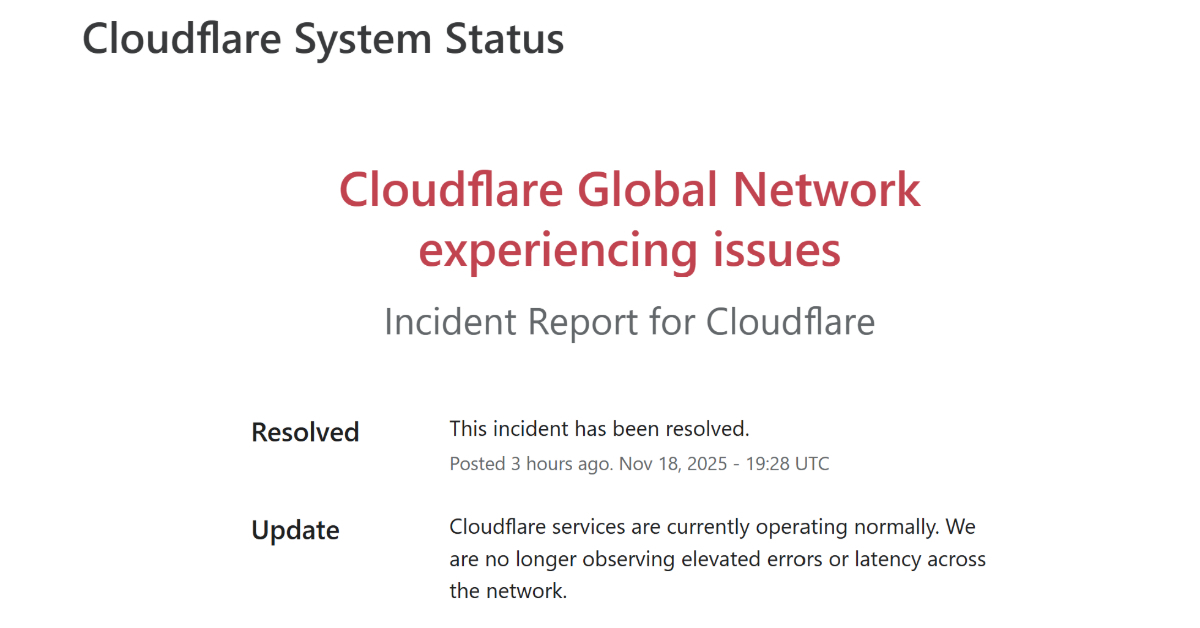
障害と同日に Cloudflare が公表したポストモーテム「2025年11月18日のCloudflareの障害」によると、今回の障害はサイバー攻撃ではなく、同社内部の設定変更に起因するものだと説明されています。
具体的には、データベース権限の変更に伴い、Bot対策用の設定ファイルに想定外の重複データが混入し、ファイルサイズが大幅に増加したことで、その設定ファイルを読み込む仕組みが一時的に正しく動作できなくなった可能性が示されています。
この設定ファイルが世界中の環境に適用されたことで、結果としてエラーが生じ、一部サービスでアクセスしづらい状況につながったと説明されています。

単一サービス依存は最大の経営リスク
Cloudflare はWebやCDN、セキュリティの分野で世界的に高い評価を受けているインフラサービスですが、それでも障害が発生する可能性はゼロではありません。障害の原因となり得るのは、設定ミスやサイバー攻撃などさまざまですが、特にサイバー攻撃は昨今激化しているため、今回のような大規模障害はいつでも起きる可能性があります。
一部ニュースサイトでは、ChatGPT や、Zoom、Microsoft Teams などのアクセス不調と Cloudflare の障害との関連性が示されましたが、これらのサービスは多くの企業にとって業務の基盤となっています。外部の障害が業務に大きな影響を及ぼす可能性があることを、改めて認識する契機になったと言えるでしょう。
特に中堅・中小企業では、運用管理などの観点から、チャットツールやAIツール、クラウドストレージなどを特定のサービスに依存する構造がよく見られます。
このような依存構造を持つ場合、今回のような障害は最悪の場合業務停止にもつながりかねません。中堅・中小企業にとっては、「単一依存の弱さ」を浮き彫りにする出来事にもなりました。
今こそ必須!BCPを整えて「リスク分散」
今回の Cloudflare の障害は、単なる技術トラブルとして片付けられるものではなく、「外部のサービスへの依存は事業継続を揺るがす可能性がある」という課題に改めて注目するきっかけになったと言えます。
事故や障害、サイバー攻撃はいずれも「いつ起きてもおかしくない」ものですが、有事の際に「誰が、何を、どう判断するか」が明確でない企業も少なくありません。
BCP(Business Continuity Plan:事業継続計画)は、有事の意思決定や行動を平常時に定めておく計画のことで、その有無によって復旧スピードや業務停止範囲が大きく変わってきます。特に中小企業では、人員やリソースの制約から「誰か一人が止まると全体が止まる」といった構造が生まれやすく、ガバナンス整備の重要性が指摘される場面も多いです。
今回の出来事を契機に、今後改めて見直すべきポイントとして、次の3つが挙げられます。
- ガバナンスの整備
- バックアップ
- セキュリティ対策
1.ガバナンスの整備
有事の際に、誰が、何を、どう判断するのか、優先すべき業務や代替手段を事前に決めておくことで、障害発生時の混乱や停止時間を最小限にできるとされています。
2.バックアップ
外部のサービスの障害やサイバー攻撃による「データにアクセスできない」状況に備え、クラウドとローカル双方へのバックアップを複数の形で保持することが望まれます。
3.セキュリティ対策
意図的な攻撃によって引き起こされるシステム障害は、そこからさらにサイバー攻撃の被害に繋がる恐れがあるため、EDRやメール対策、資産管理など、基本的な防御の整備が欠かせません。特に今回のような大規模障害のタイミングでは、フィッシングメールのようなソーシャルエンジニアリングが増える可能性が高まるとされています。
.png?fm=avif&w=200&q=30)
企業経営が外部のサービスへ依存が強める中、それらの障害がいかに大きな影響を及ぼすかは、今後も意識しておく必要があります。
とはいえ、過度に不安を感じる必要はありません。企業にできる対策は決して複雑ではなく、基本の「ガバナンス」「バックアップ」「セキュリティ」という3つの柱を見直すだけでも、有事の際の対応力は大きく向上します。できるところから、できるだけ早くBCPを整備していきましょう。
執筆者
